

L’année 2022 a été marquée par de sévères licenciements dans les grandes entreprises technologiques(nouvelle fenêtre), une possible interdiction de TikTok aux États-Unis(nouvelle fenêtre), suivie début 2023 d’une nouvelle fuite de données chez Twitter. Mais le fait le plus marquant de cette nouvelle année est sans aucun doute l’ascension de ChatGPT(nouvelle fenêtre).
Le robot conversationnel peut produire un texte remarquablement humain et, selon le prompt (la commande écrite envoyée à l’intelligence artificielle), il peut même générer des réponses créatives qui ne semblent pas pouvoir être générées par un ordinateur :
La vitesse des progrès est stupéfiante. Et si l’on se fie aux technologies précédentes, ce phénomène ne fera que s’accélérer. La génération actuelle de robots conversationnels (chatbots) a déjà surpassé le test de Turing. Il est donc très probable que ces robots alimentés par l’intelligence artificielle (IA) seront bientôt appliqués à toutes sortes d’emplois, de tâches et d’appareils dans un avenir proche. Ce n’est qu’une question de temps avant que l’interaction avec l’IA ne fasse partie de notre vie quotidienne. Cette prolifération ne fera qu’accélérer le développement de l’IA.
C’est une bonne nouvelle ! L’IA est un outil puissant qui pourrait déboucher sur toutes sortes de nouveaux développements et de découvertes. Néanmoins, comme pour tout outil, nous devons veiller à ce qu’il soit utilisé et développé de manière responsable. Nous avons remarqué, chez Proton, que malgré toute la publicité faite autour de ChatGPT, les questions de protection de la vie privée soulevées par l’IA n’ont pas été abordées.
On vous explique comment l’IA, comme ChatGPT, a besoin de données pour se développer et comment elle pourrait représenter de nouveaux défis pour la protection de notre vie privée à l’avenir.
Nous avons même interrogé ChatGPT sur l’avenir de la protection de la vie privée et il nous a donné de bonnes réponses.
Vous pourrez découvrir la suite de notre conversation avec ChatGPT(nouvelle fenêtre) dans les prochains jours.
Former l’IA nécessite des données (beaucoup de données)
D’énormes quantités de données sont nécessaires pour entraîner et améliorer la plupart des modèles d’IA. Plus l’IA est alimentée en données, plus elle est capable de détecter des modèles, d’anticiper ce qui va suivre et de créer quelque chose d’entièrement nouveau. Le processus se déroule à peu près de la manière suivante :
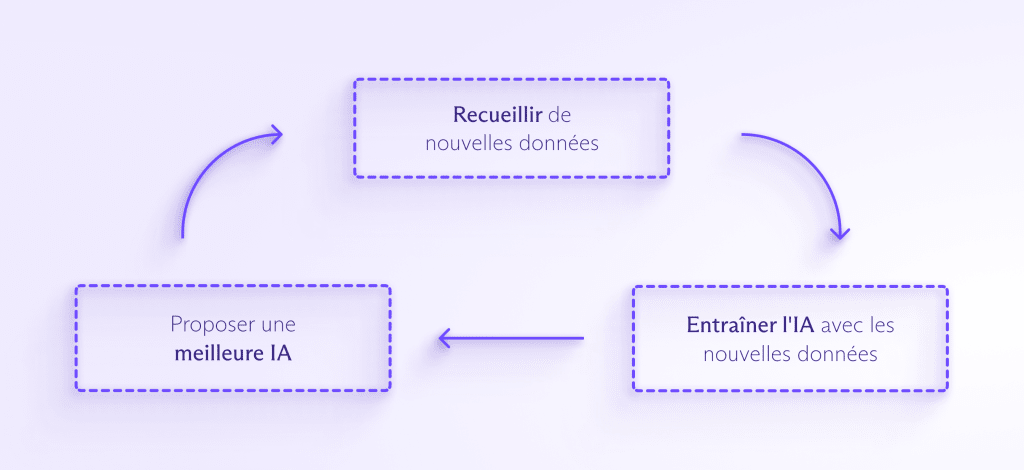
L’intégration de l’IA dans un plus grand nombre de produits de consommation entraînera une pression pour collecter encore plus de données dans le but de l’entraîner. Comme les gens interagissent de plus en plus souvent avec l’IA, les entreprises voudront probablement collecter vos données personnelles pour aider votre assistant IA à comprendre comment vous répondre, individuellement.
Cela entraîne toutes sortes de problèmes. Une IA entraînée à partir de données apprendra uniquement à traiter les situations soulevées par l’ensemble des données qu’elle a pu analyser. Si vos données ne sont pas représentatives, l’IA reproduira ce biais dans ses décisions. C’est exactement ce qu’Amazon a constaté quand son robot de recrutement a pénalisé les femmes(nouvelle fenêtre) après avoir été formé sur des CV dans un ensemble de données à prédominance masculine.
De même, si l’IA rencontre une situation qu’elle n’a jamais vue dans ses données d’apprentissage, elle risque de ne pas savoir comment réagir. Cela a été le cas d’un véhicule Uber à conduite autonome qui a tué un piéton(nouvelle fenêtre) qu’il n’a pas identifié parce que la personne se trouvait en dehors d’un passage pour piétons.
Et avant qu’une IA puisse être entraînée sur des données, celles-ci doivent être nettoyées, ce qui suppose de les formater correctement et de supprimer les contenus racistes, sexistes, violents ou répréhensibles. Tout comme la modération de contenu pour des entreprises comme Meta, ce travail est généralement éreintant, mal rémunéré et invisible pour le public. On a récemment appris qu’OpenAI avait fait appel à des centaines de personnes au Kenya(nouvelle fenêtre) pour nettoyer les données de GPT-3, qui ont fini par être traumatisées par ce travail.
Pour que l’IA puisse éviter ces types de biais et de zones d’ombre, les entreprises devront collecter encore plus de données que les grandes entreprises technologiques ne le font actuellement pour vendre des publicités personnalisées. Vous ne le savez peut-être pas, mais ces démarches ont déjà commencé.
Pour donner un exemple de l’échelle dont nous parlons, l’ensemble du site Wikipedia en anglais, qui comprend quelque 6 millions d’articles, n’a représenté que 0,6 % des données d’entraînement pour GPT-3(nouvelle fenêtre), dont ChatGPT est une variante.
Un exemple plus connu est celui de Clearview AI(nouvelle fenêtre), qui a récupéré les images de personnes sur le web et les a utilisées pour entraîner son IA de surveillance faciale, sans le consentement des personnes en question. Sa base de données contient environ 20 milliards d’images.
Clearview a fait l’objet de toutes sortes de poursuites judiciaires, d’amendes et de mises en demeure pour son mépris flagrant de la vie privée. L’entreprise a toutefois réussi à éviter de payer de nombreuses amendes et a refusé de supprimer des données malgré les injonctions des régulateurs(nouvelle fenêtre), ouvrant potentiellement la voie à d’autres développeurs d’IA peu scrupuleux.
Autre inquiétude : l’omniprésence de l’IA pourrait rendre cette collecte de données presque impossible à éviter.
L’IA va traiter votre dossier
Nous nous inquiétons aujourd’hui de la quantité de données que les géants de la tech collectent à notre sujet pendant que nous naviguons en ligne ou par le biais d’appareils intelligents connectés à internet. Le nombre d’appareils intelligents et la quantité de données collectées vont exploser à mesure que l’IA et les robots conversationnels s’améliorent. L’IA commencera à envahir les parties de notre vie qui sont déjà dominées par les algorithmes et il sera impossible d’y échapper.
Aujourd’hui, selon votre lieu de résidence, un algorithme pourrait décider si vous êtes libéré sous caution(nouvelle fenêtre) avant votre procès, si vous pouvez contracter un prêt immobilier(nouvelle fenêtre) et combien vous devez payer pour votre assurance maladie(nouvelle fenêtre). L’IA se chargera de ces questions essentielles et s’étendra probablement à d’autres secteurs. L’utilisation de l’IA pour prédire la criminalité(nouvelle fenêtre) semble faire l’objet d’une quête sans fin. Des expériences ont déjà été menées en utilisant GPT-3 comme robot conversationnel médical(nouvelle fenêtre) (avec des résultats désastreux).
À mesure que l’IA est appliquée à de nouvelles fonctions, elle sera exposée à de plus en plus d’informations sensibles et il sera de plus en plus difficile pour les gens d’éviter de partager leurs informations avec l’IA. Par ailleurs, une fois les données collectées, il est très facile de les réaffecter ou de les utiliser à des fins auxquelles les personnes n’ont jamais consenti.
Nous ne savons pas à quoi ressemblera l’IA de demain
Jusqu’en 1965, les ordinateurs occupaient des pièces entières(nouvelle fenêtre). C’est cette même année que Gordon Moore a énoncé ce que l’on a appelé la Loi de Moore(nouvelle fenêtre), qui stipule que le nombre de transistors que l’on peut placer sur une puce de microprocesseur doublera tous les deux ans. Sa prédiction s’est révélée exacte pendant plus de 40 ans et ne s’est démentie que récemment. Mais même lui n’aurait pas pu prédire à quel point nos ordinateurs actuels sont évolués.
Il est fort probable que nous regarderons ChatGPT de la même manière que nous regardons un ordinateur des années 60, émerveillés de voir comment il était possible de faire quoi que ce soit avec. Nous sommes au début d’un voyage technologique d’une importance cruciale et nous n’avons aucune idée de l’endroit où il nous mènera.
Actuellement, les gens s’inquiètent de la manière dont les plateformes des grandes technologies peuvent subtilement influencer notre prise de décision et créer des sphères de filtrage impossibles à fuir. Toutefois, ces instruments peuvent sembler peu efficaces par rapport à un moteur de recherche doté d’une intelligence artificielle ou à un nouveau service. De plus, l’IA pourrait devenir si performante en matière de reconnaissance des formes qu’elle développerait la capacité de désanonymiser les données ou de faire correspondre les identités dans des ensembles de données disparates. Tout cela semble spéculatif, mais c’est simplement parce que nous n’avons aucune idée des limites des capacités de l’IA.
Que pouvons-nous faire pour préserver la vie privée dans un avenir dominé par l’IA ?
Bonne nouvelle : il y a des choses que nous pouvons faire dès maintenant pour nous assurer que l’IA est entraînée de manière responsable en utilisant des données anonymes. Nous prévoyons d’écrire un autre article sur les méthodes que les entreprises peuvent utiliser pour entraîner l’IA sur des ensembles de données tout en protégeant la vie privée des internautes.
Si votre vie privée vous tient à cœur, vous pouvez commencer à protéger vos informations. Si vous chiffrez vos données (avec des services comme Proton Mail ou Proton Drive), vous les retirez des bases de données des géants de la tech ou des bases de données publiques, ce qui empêche qu’elles soient utilisées pour vous suivre ou pour entraîner l’IA.
Vous pouvez aussi utiliser des sites comme Have I Been Trained(nouvelle fenêtre) pour voir si l’une de vos images a déjà été utilisée pour former l’IA. Malheureusement, même si vous découvrez que l’une de vos images a été utilisée sans votre autorisation, il n’est pas toujours facile de savoir comment la faire retirer(nouvelle fenêtre).
Quant aux décideurs politiques, ils peuvent commencer à définir un cadre d’utilisation de l’IA qui intègre le droit au respect de la vie privée. Mais nous devons agir maintenant. L’IA se développera probablement à un rythme exponentiel, nous devons donc répondre à ces questions maintenant, avant qu’il ne soit trop tard.
La première chose à faire est que chaque pays adopte une loi sur la confidentialité des données qui limite les types de données personnelles pouvant être collectées et l’utilisation légale de ces données. Il serait alors plus facile de sanctionner des entreprises comme Clearview AI.
À l’avenir, les décideurs politiques peuvent exiger que les entreprises d’IA fassent preuve de transparence sur le fonctionnement de leurs algorithmes et modèles d’IA, ou au moins sur les ensembles de données qu’elles utilisent pour entraîner leurs systèmes. Cela permettra aussi à ces entreprises d’éviter de perpétuer les biais et les zones d’ombre de l’IA que nous avons évoqués plus haut.
Les décideurs politiques devraient par ailleurs obliger les entreprises d’IA à soumettre leurs modèles à des audits réguliers et à faire appel à des responsables indépendants de la confidentialité des données pour s’assurer que les données sont utilisées de manière responsable.
Nous vivons un moment passionnant de l’histoire de l’humanité. L’IA est un territoire inexploré, mais avant de nous y aventurer, nous devons nous assurer que nous avons garanti nos droits fondamentaux.
Dernière mise à jour le 30 janvier 2023 : nous avons supprimé une référence au fait que les travailleurs qui nettoyaient les données pour ChatGPT étaient mal payés après la publication des montants versés.
—
Traduit et adapté par Elodie Mévil-Blanche.






